


出品|搜狐科技
作者|郑松毅
编辑|杨锦
剑指谷歌,OpenAI甩大招!
数小时前,GTP-5.2强势发布。此次更新被业界视为OpenAI对谷歌Gemini 3的直接回应,也标志着AI大模型竞争进入“实用主义”新阶段。
与以往不同,GTP-5.2的更新不再是炫技,而是更贴合“高级打工人”身份,在专业任务处理、长文本推理、编程开发等核心能力上实现突破性提升,尤其瞄准职场生产力场景,号称可让重度用户每周节省10小时以上工作时间。
本次更新包含GPT-5.2 Instant、Thinking与Pro三个版本:分别面向快速响应、深度推理与高质量输出三大场景。
即日起,Plus、Pro、Business与Enterprise等付费方案用户可率先体验,Free与Go用户预计将于明日获得访问权限。
据OpenAI官方数据,GPT-5.2在多项基准测试中刷新行业纪录。用一句话概括,在搞定复杂物理世界任务方面,GPT-5.2已经做到最强。
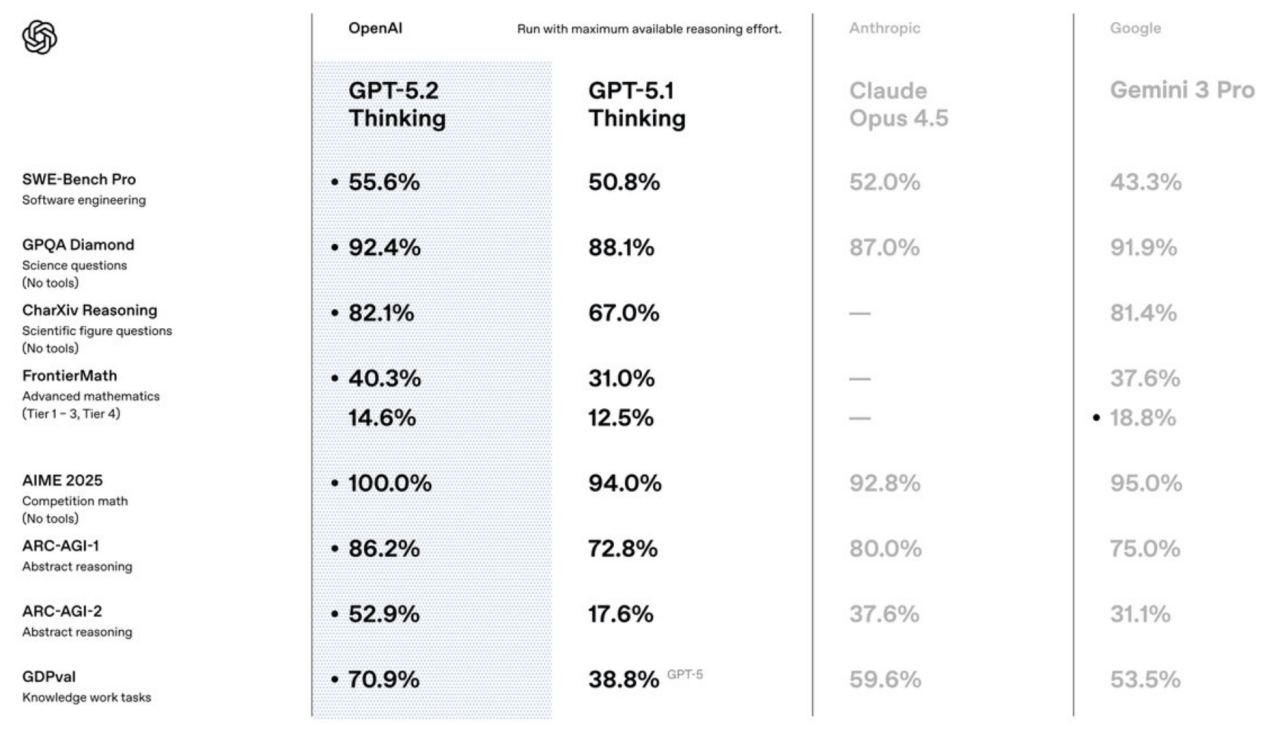
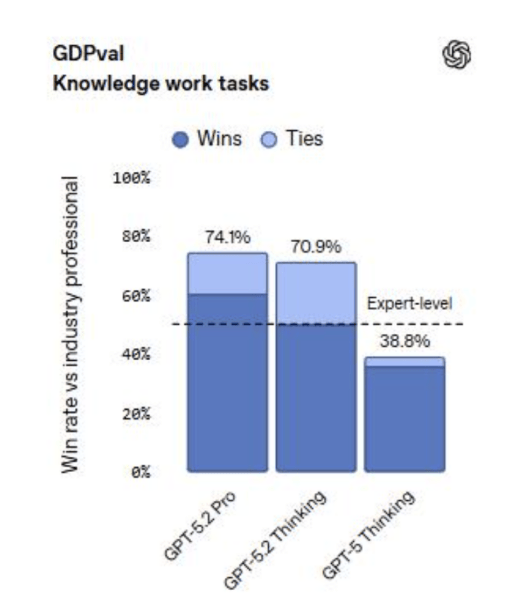
在GDPval测试中,GTP-5.2在涵盖44个职业的工作任务上,最高有74.1%的表现达到或超越行业专家水平。OpenAI介绍,“GPT-5.2 Thinking完成这些任务的速度是专家的11倍以上,成本不到专家的1%。”
来看看GTP-5.2做的统计表,是不已经赶超了不少打工人水准?
智能编码方面,GTP-5.2上分到了王者段位。在现实世界软件工程基准测试SWE-Bench Pro中,GTP-5.2 Thinking创下了55.6%的新纪录。
SWE-Bench Pro测试被业界视为编码“试金石”,同时测试四种编程语言,且测试题目涵盖高工业相关性、多样性,更具挑战。
在SWE-Bench Verified上,GTP-5.2 Thinking更是一举拿下80%的高分。
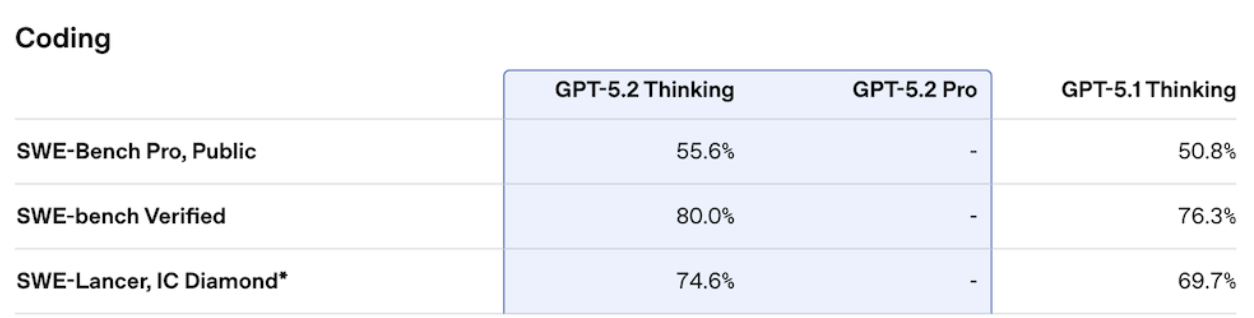
这意味着,它可以更可靠地完成生产环境代码调试、功能实现与大型代码库重构,减少对人工干预的依赖。
测试者发现,GTP-5.2在前端开发表现方面较上一代模型亦有显著提升,仅凭单一提示词即可生成带可调参数与逼真动画的完整单页应用。
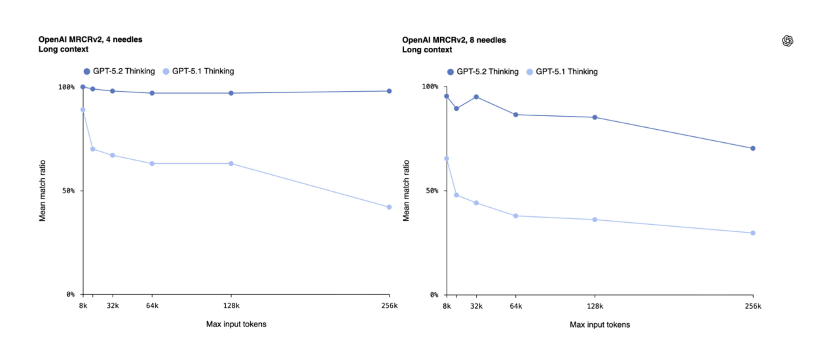
长文本推理与视觉理解能力的升级同样值得关注。在MRCRv2基准测试中,GPT-5.2对数十万token跨文档信息的整合准确率远超前代,尤其在256k token上下文的多“针”识别测试中接近100%准确率,可高效处理百页级报告、合同、学术论文等超长文本。
视觉领域,其图表推理与软件界面理解错误率下降约一半,能精准解读数据仪表盘、技术图纸等视觉材料,适配金融、工程、设计等多行业场景。
科研辅助能力的进阶成为本次发布的“硬核亮点”。 GPT-5.2 Pro版在ARC-AGI-1测试中(衡量通用推理能力),成为第一个突破90%准确率的模型,成本较此前降低390倍。且模型整体幻觉率降低,为专业研究、决策支持等关键任务提供更可靠保障。

OpenAI介绍,在统计学习理论的一个开放难题——《关于最大似然估计量的学习曲线单调性》上,GPT-5.2直接给出经专家验证的可行证明方案,目前该篇论文已经发表。展现出AI在数学、理论计算机科学等公理基础明确领域的实质性科研价值。
API方面,GPT-5.2定价为每百万输入token 1.75美元、输出token 14美元;Pro版本最高支持“xhigh”第五档推理强度,定价为每百万输入token 21美元,输出token 168美元。尽管单价上涨,OpenAI强调,因模型效率提升,实际使用成本反而下降。

此次发布正值全球大模型市场从技术比拼转向应用落地的关键时期。国内外“Gemini”“Grok”、“千问”“Kimi”等产品正通过场景整合及降低应用成本抢占市场,行业竞争从跑分竞赛转向看谁能够精准满足用户需求。
北京邮电大学人机交互与认知实验室主任刘伟指出,“面对密集的产品发布,市场不乏‘重复建设’和‘内卷’的争议。大模型竞争的本质是‘技术竞争下的应用突围赛’,头部产品已经通过差异化定位形成独特的竞争力。”
新模型发布后,OpenAI CEO山姆·奥特曼在X平台发推文表示,“过去的十年非常精彩,OpenAI的工作比我想象的还要特别。”

他透露,圣诞节还会为大家带来一个“礼物”,下周就会推出,大家猜猜会是什么呢?
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏






