


文 | 孙永杰
近日,美国政府宣布放宽对英伟达H200 AI芯片的对华出口管制,这一决定本应为中美科技合作注入新活力。然而,中国商务部及网信管理部门随后明确,将继续对进口高端芯片实施更为严格的安全与合规审查,并在新建数据中心审批中强调优先采用国产算力方案,如华为Ascend系列AI芯片。这一被外界概括为“原则上限用、慎用”的回应,引发了产业界的广泛讨论。表面上看,这种态度似乎体现了中国对国产AI芯片能力的信心,实则是中美在AI算力领域的复杂博弈。
H200的性能真相,不可忽视的系统级代差压制
在当前国内的舆论语境中,常有一种“国产芯片已能平替英伟达”的乐观情绪,依据则是“参数对照式”的对比,例如看制程、TFLOPS、显存容量,然后得出“差距正在缩小”的判断。这种分析在早期硬件竞赛中尚有意义,但在当下的大模型时代,已经越来越难以解释真实差距。
究其原因,大模型训练早已不是“单卡性能竞赛”,而是一场关于规模、稳定性与系统协同能力的长期工程,而随着模型参数从百亿级迈向万亿级,任何局部短板都会在系统层面被迅速放大。
正是在这样的背景下,近年来,国际研究机构和云服务商越来越多地引入类似TPP(Total Processing Performance)总处理性能的综合指标,用以衡量在真实训练场景中,单位时间、单位资源所能进行的有效计算量。这类指标往往会“惩罚”通信效率不足、内存瓶颈突出或软件调度不成熟的AI算力系统。而若以此为标准,H200对国产AI芯片形成的其实是系统级的代际压制。
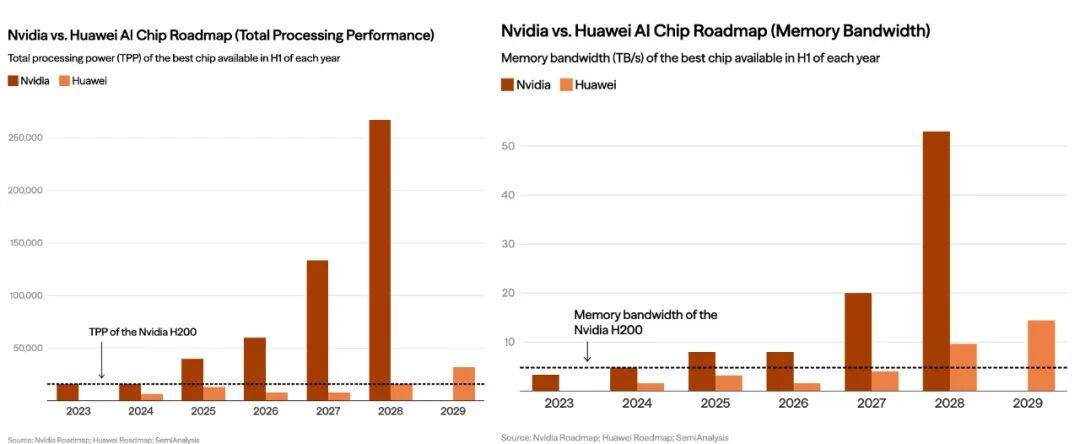
根据美国对外关系委员会(CFR)的题为《China’s AI Chip Deficit: Why Huawei Can’t Catch Nvidia and U.S. Export Controls Should Remain》的分析报告显示,英伟达的领先地位不仅源于其计算核心,更在于其构建的“全栈式”硬件集成。具体到H200,作为Hopper架构的巅峰之作,其TPP指标高达15,832。相比之下,作为国产算力标杆的华为昇腾910C,虽然在设计上极力追赶,但受限于国内制程工艺的物理上限,其TPP指标约为12,032,而这种差距在处理万亿参数级的大模型时还会被呈指数级放大。
此外,H200配备了高达141GB的HBM3e内存,带宽达到惊人的4.8TB/s,这比国产芯片普遍采用的HBM2e高出一个代际,使得在实际的混合精度训练中,H200的有效算力释放效率往往是国产芯片的5-6倍。这意味着,同样的模型训练任务,使用英伟达集群可能只需要3个月,而国产集群可能需要18个月甚至更久,且面临更高的硬件故障率。
最后是在互连效率与软件生态上,英伟达NVLink与CUDA构成的护城河更是难以逾越的鸿沟。正基于此,H200的系统级互连能力使得8卡、72卡乃至整个机架能够像一个单一处理器一样协同工作,通信损耗极低。相较之下,中国所谓的“万卡集群”目前仍处于“物理数量达标、逻辑调度低效”的阶段(据称国产芯片在跨节点通信时性能损耗高达30%以上),导致其集群算力优势大打折扣。
除上述外,如CFR报告所言,华为及其国内同行还面临美国对先进封装(CoWoS)和HBM3e供应链的严密封锁,使得到2027年,随着Blackwell系列的全面普及,英伟达顶配芯片的性能预计将达到华为同期昇腾芯片的17倍,集群算力差距更可能拉大到21—49倍。而正是这种“领先一个身位”的策略,实质上是将中国锁死在“逻辑上能运行、工程上难超越”的次级算力圈层中。
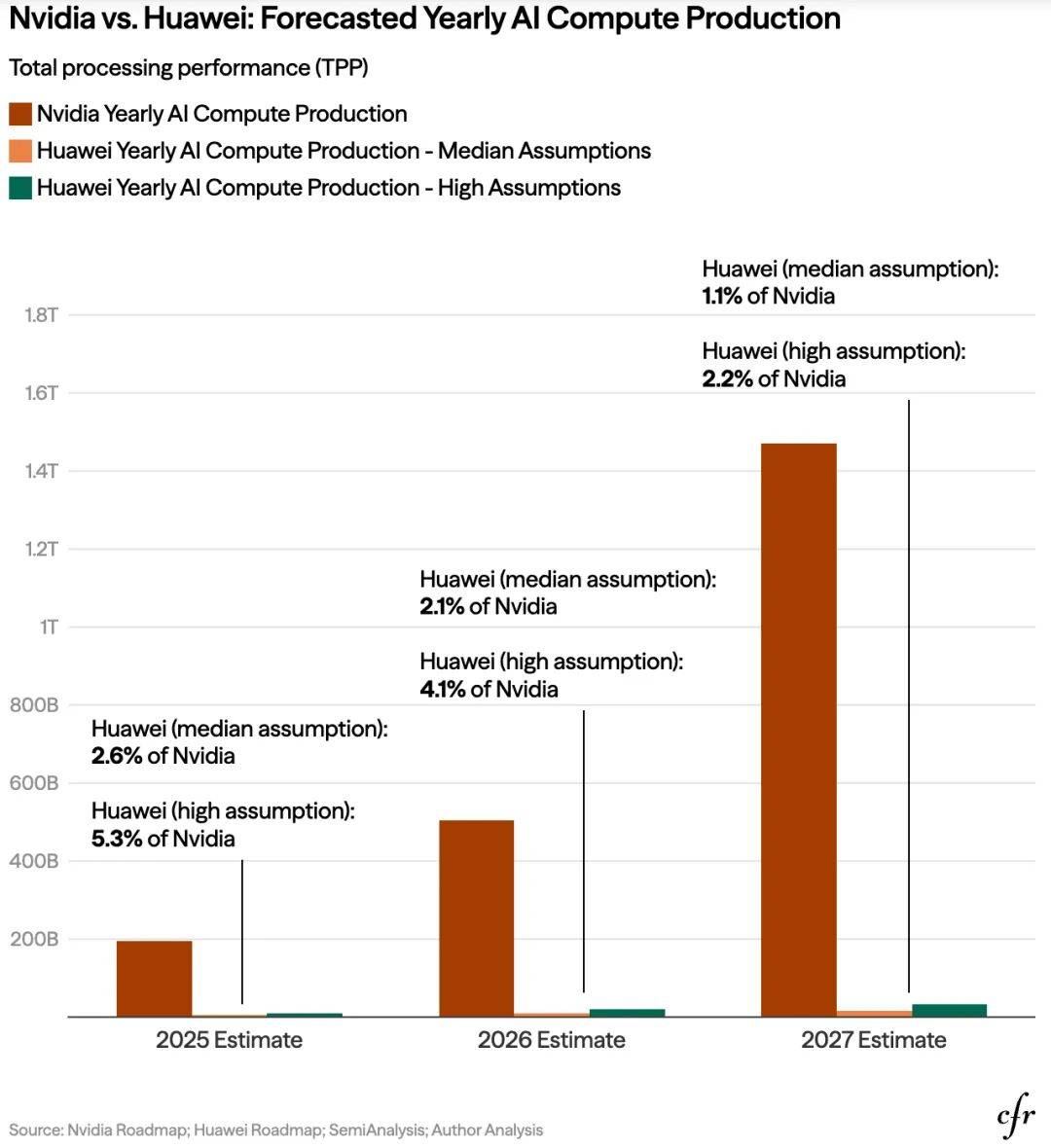
从这一意义上说,H200 的优势并非体现在“是否遥遥领先”的情绪化判断,而在于其是否具备支撑下一代基础模型长期、稳定训练的系统能力。在这一维度上,中国整体仍处于追赶区间。
中国“谨慎对待”背后,现实局限与策略选择的博弈
既然H200在系统层面仍具明显优势,中国为何在政策层面表现出相对谨慎甚至克制的态度?在我们看来,这并非简单的技术自信,而更多源于现实局限与策略选择的综合考量。
首先需要指出的是,国内头部AI企业或团队获取先进算力的实际路径,已不完全等同于公开、合规的商业进口渠道。近年来,国际执法部门披露的一些案件显示,全球高端芯片流通中确实存在复杂的灰色网络。尽管这类现象并非中国独有,但客观上影响了部分机构对“次优合规方案”性价比的判断。当然,这一因素更多属于边际影响,而非主流供给路径,仍需理性看待。
此外,长期以来,国内普遍认为中国在电力和能源基础设施方面具备结构性优势,这在一定阶段内确实为算力扩张提供了条件。
然而,Epoch AI最新的报告《Is almost everyone wrong about America’s AI power problem?》则给出了不同结论。该报告分析称,虽然美国电网陈旧、审批缓慢,但美国正利用极其灵活的资本手段进行“能源突击”。
例如,xAI可以在几周内通过快速部署大规模天然气轮机解决电力需求,而微软、谷歌等巨头正通过重启核电站、推进小型核反应堆(SMR)等方式逆转电力瓶颈。对此,Epoch AI认为,美国拥有庞大的需求响应能力(容量达76-126 GW),完全有能力支撑未来100 GW以上的AI算力电力需求。由此看,我们业内眼中的所谓中国电力红利其实更像是一种“阶段性红利”,而非制约美国的长期结构性壁垒。
最后,也是最残酷的差距在于先进制程的“产量控制”。据OECD 2025年《THE CHIP LANDSCAPE》的报告,在7nm及以下制程的逻辑芯片产能上,美国与中国台湾阵营仍占据80%以上的市场份额。具体表现为中国先进逻辑芯片产能仅为0.39百万WSPM,美国为0.84、中国台湾1.55,而到2030年,美国将新增0.62百万WSPM先进逻辑芯片,中国仅为0.38。
与此同时,由于缺乏EUV光刻设备,中国先进逻辑芯片产能只能高度依赖多重曝光工艺,导致国产芯片不仅性能落后,其量产良率也极低(据称是我们20%-40%对比台积电的90%以上),进而导致单颗国产芯片的生产成本甚至高于英伟达的市场售价。在这一背景下,通过政策手段为国产算力争取应用空间,更多是一种现实局限下的产业保护与培育策略。
应对与破局,从“单点替代”走向生态重构
如果说我们前述解释了“差距为何存在”,那么真正决定未来走向的,是中国如何应对这一差距。而在此过程中,一个值得警惕的倾向是,算力问题在国内的舆论中常被简化为“某一家国产芯片企业能否追上英伟达”。其实这种叙事除了容易制造情绪,更可能掩盖了重要的现实,那就是算力体系从来不是由单一企业支撑,而是一个高度复杂,跨越芯片、系统、软件和组织方式的系统工程。
基于此,面对中美AI算力的全方位代差,中国AI产业的应对策略亟待从“单向平替”到“生态重构”的根本性转变。
众所周知,过去几年,国内过分押注某单一“国家队”芯片虽然取得了阶段性成果,但也暴露出生态路径单一、风险集中等问题。因此,未来的破局方向,更可能在于多路径并行的生态构建。
例如近期摩尔线程(Moore Threads)、沐曦(Muxi)、壁仞(Biren)等国产GPU新势力的密集上市,就反映了国家对“多路径探索”战略的认可。而这些企业通过在图形渲染、国产集群适配以及针对特定算法(如DeepSeek的MLA架构等)的深度优化,正在构建一个比单一企业更具韧性的生态体系。
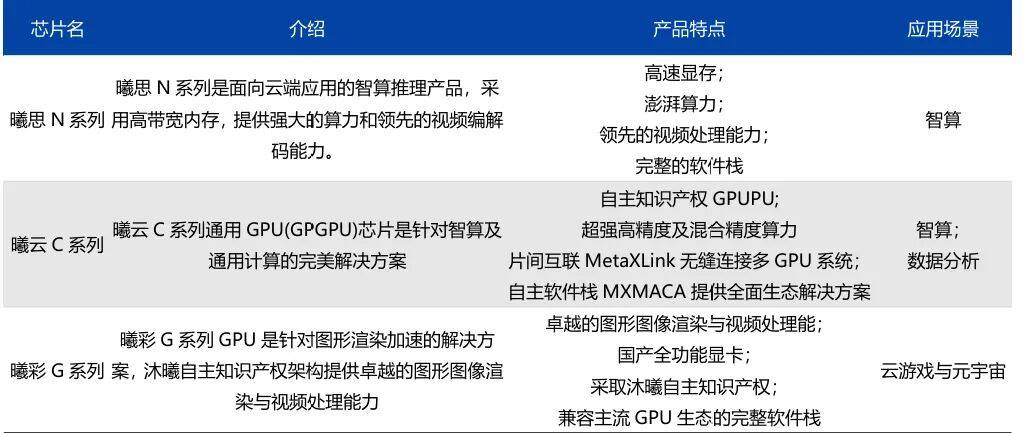
沐曦股份主要产品分类,来源:沐曦股份公司官网,爱建证券研究所
同理,除了上述所谓国产AI芯片的新势力外,以海光信息为代表的“老牌国家队”则展现出一种更为成熟的破局逻辑,即在保持底层自主可控的同时,最大限度兼容主流软件与开发范式,通过与大量ISV的协同,降低生态迁移成本。而这类“兼容主流、逐步替代”的路径,可能在中长期内为国产算力提供缓冲空间。
除上述之外,中国此前通过DeepSeek在算法层面展现出的“以小博大”的能力,则是弥补我们算力代差的最后变量。当硬件TPP落后时,通过极致的算法重构(如MoE、MLA优化)来提升存量算力的利用效率,是中国AI算力通往“DeepSeek时刻”的关键。
由此可见,未来的希望不在于某一家企业超越英伟达,必须是全产业链的共同努力,即在老牌国家队的生态托底、新势力的技术突围以及模型厂商的算法优化下,共同构建一个不被外部定义和具备产业韧性的自主AI算力生态体系。
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏






